
Amazon Web Services (AWS) introduced a new 64-bit ARM Neoverse core which they named Graviton2 about a year ago with wide availability in June 2020. Marketing claims they provide up to 40% better price performance over x86-based instances. A footnote clarifies with “20% lower cost and up to 40% higher performance based on internal testing with varying characteristics of compute and memory requirements”. As you know, details can be important....
2019 HPCwire Editors’ Choice Award
Work on standing up a 1 million-vCPU AWS cluster won a 2019 HPCwire Editors’ Choice Award!...
light-weight way to capture results from cloud HPC/HTC
For large HTC (or HPC) computations on the cloud, ‘spot instances’ (AWS-speak), ‘low-priority VM’ (Azure-speak) or ‘preemptible VM instances’ (GoogleCloud-speak) are the low cost options for compute. Of course, the challenge here is that these instances/VM can vanish at anytime. If you’re doing a large HTC task, you want to make sure you save your result (and/or checkpoint) files as soon as they are generated to persistent storage. Otherwise you lost the computation you just paid for....
cost effective high-throughput computing in the cloud
High-throughput computing (HTC) is the term to describe the use of many computing resources over long periods of time to accomplish a computational task or job. Robustness and reliability of jobs over a long-time scale is a key concern. The metric for HTC is jobs per month. Typically the jobs are loosely-coupled....
persistent storage (part 2)
In a previous post, we show how to ‘randomize’ names on object base persistent storage to avoid service rate limits. We did not actually reduce the cost of object storage....
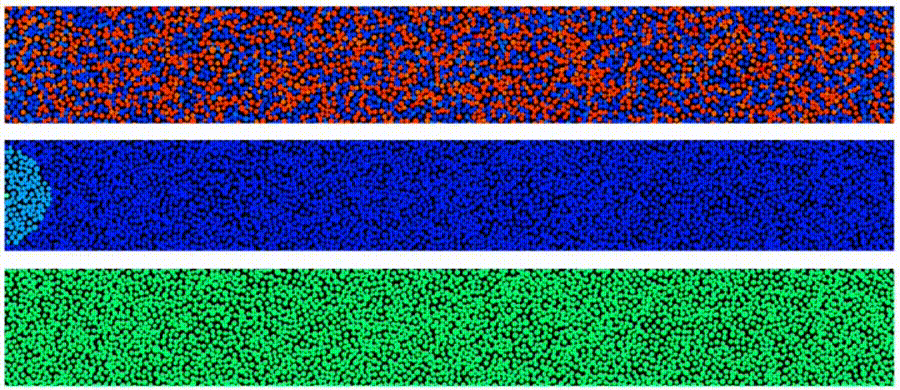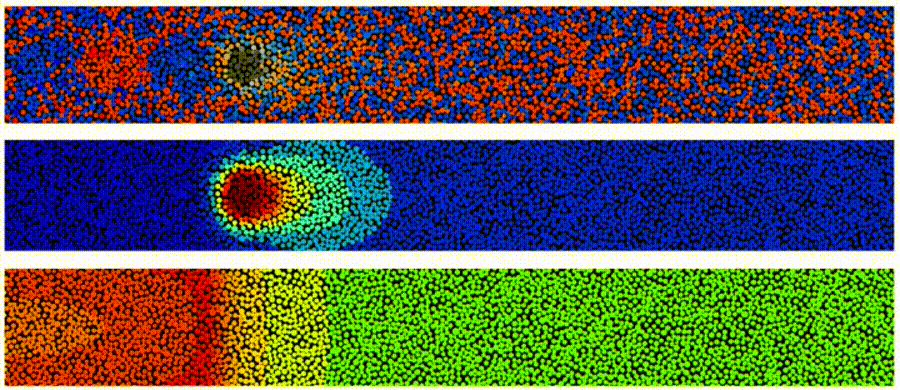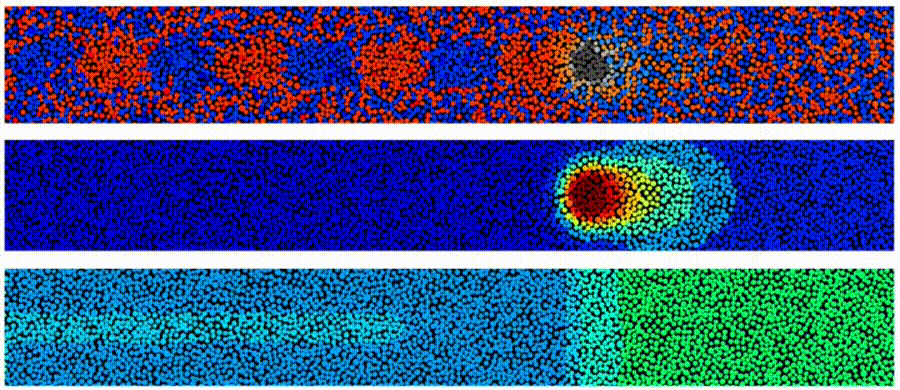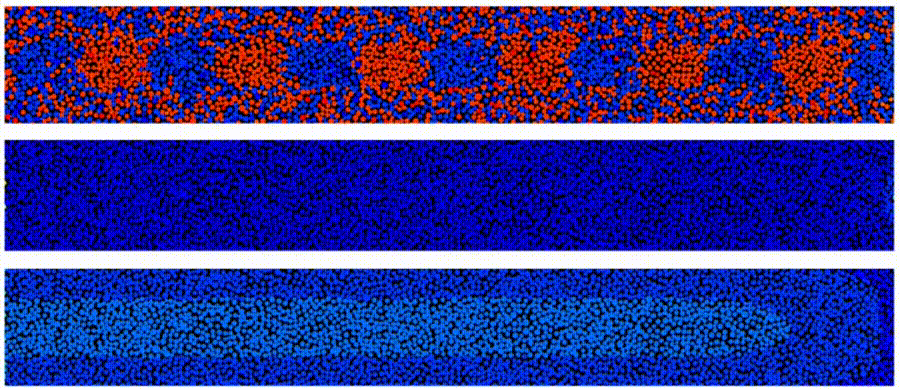
“one million core” cluster in the cloud
Originally posted on LinkedIn. A more technical presentation from HEPiX Spring 2019 Workshop @ UC San Diego, CA, USA. This work won the 2019 HPCwire Editors’ Choice Award for Best Use of HPC in Manufacturing....