
Originally posted on LinkedIn. A more technical presentation from HEPiX Spring 2019 Workshop @ UC San Diego, CA, USA. This work won the 2019 HPCwire Editors’ Choice Award for Best Use of HPC in Manufacturing.
An adventure to a robust and efficient tool so my [previous] job could do itself.
Recently, Western Digital, AWS and Univa have been discussing a “1 million core HPC cluster” spun up on AWS. I’ve read many of these articles/talks. None really say how it was done or, even, what was done. I understand getting an eye catching headline is important, but sometimes you really want to know what was done. Fortunately, I was in the middle of this torrent. So, for my fellow nerds, buckle in and let me tell you what was done.
The purpose of spinning up such a vast HPC cluster was to answer a simple question: “What is the ultimate areal density (AD) that heat assisted magnetic recording (HAMR) can achieve?” AD is simply how many bits of information can be stored in a given area in a hard disk drive (HDD). Answering such a question often sets priorities in R&D but are fraught with ambiguities. The ultimate AD will not be achieved for another 5-10 years and therefore to answer the question today, some assumptions need to be made about the many components in HDD: granular magnetic medium which stores the information, magnetic writer that generates the bits, magnetic sensor to read back what was written, signal processing (a.k.a. channel modeling) to recover the actual user data and a recording scheme are the main components. All of these components interact and eventually limit AD in different ways. So, the more interesting and fruitful question is “What are feasible paths to reach this ultimate AD?”
In order to arrive at a solution, a physics based simulation tool is used to follow the dynamics of each magnetic grain in the medium during the write process. This is then followed by another physics based simulation to read back the simulated write pattern produced. Finally, these read back signals are fed into a signal processing module that determines the bit error rate (BER) of the simulated recording. The BER ultimately decides the magnitude of the computational task. A BER of 1% would mean out of 100 writes, one failure would occur during read back. No one would use such a storage solution. A BER of less than 0.001% is of more interest. However, to simulate such a low BER would require multiples of 1/BER written bits. This is why such a large scale is needed- we are trying to find rare events [that’s strictly true but a priori information can reduce the burden…]. Therefore, the simulation of writing to the magnetic granular medium is by far the most demanding computational task since we simply need a large sample size. Physically, the write process is governed by a dynamic non-linear stochastic integro-differential vector equation for each grain’s magnetic moment. A single threaded code (with memory footprint of ~50MB – 250MB) was implement to simulate the write process and was used in this “1 million core” trial.
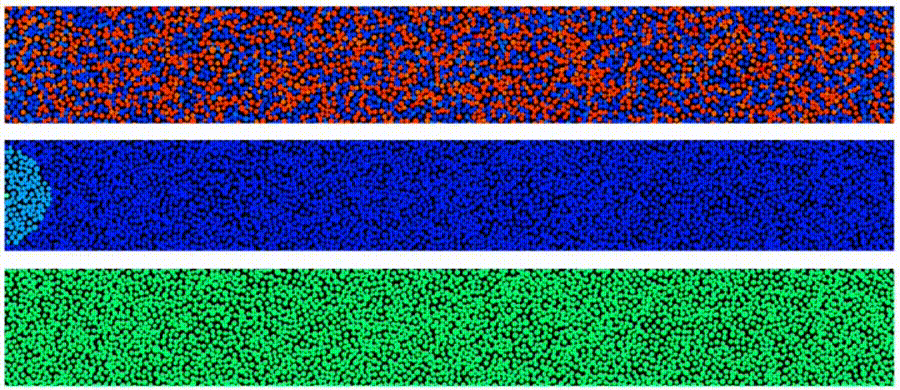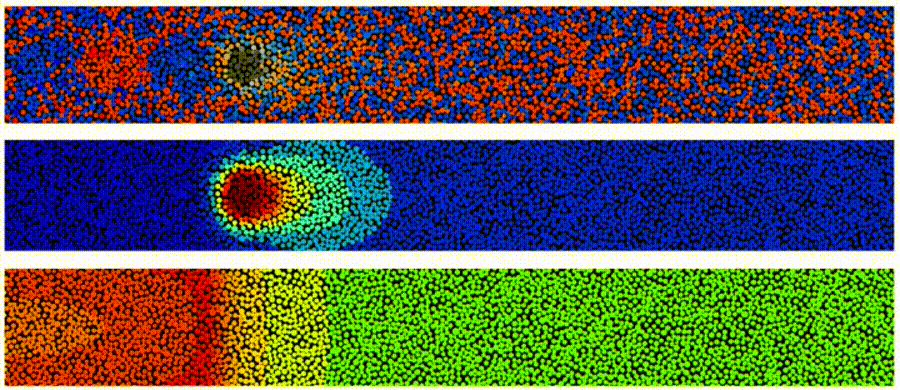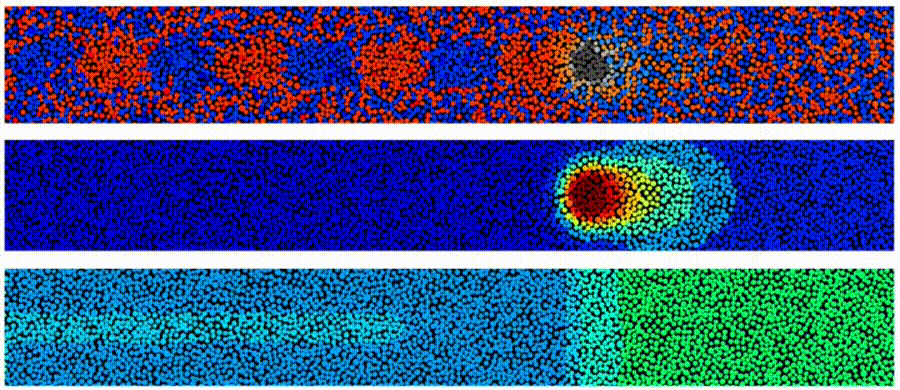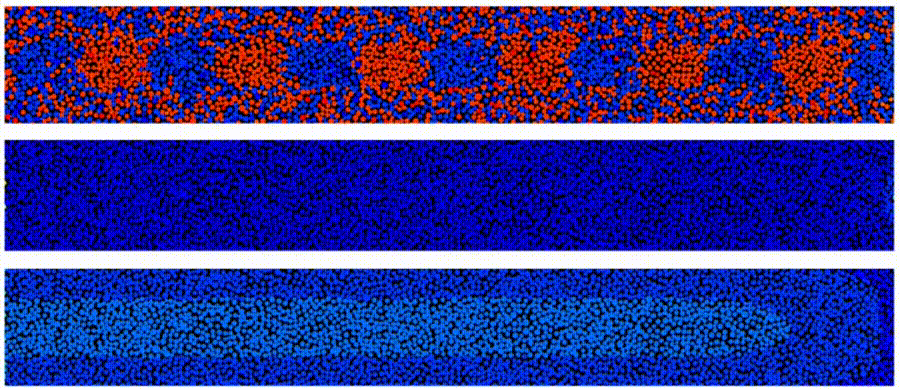
Here is a simple example of the write process during HAMR. Each panel shows the granular magnetic medium. The top panel shows the magnetization for each grain: red is pointing up while blue is down. The second panel shows the temperature (red is hot) in the granular medium as the laser is swept from left to right while the bottom panel shows the magnetic write field (again red is up while blue is down) that determines the written bit pattern. Notice in the top panel the grains that correspond to the highest temperature are neither blue or red. The reason for this is that these grains are at a high enough temperature they went through a phase transition from ferromagnetic to paramagnetic- some fascinating physics here. The panels represent recording a “single tone” (all bits have the same length) on a single track. To derive AD, we also need to write neighboring tracks (not shown) and an important question is how close these neighboring tracks can be without degrading our main data track. The vast scale of the cloud allows one to run 1, 10, 100, …, 1,000,000 such simulations concurrently.
So, that’s what was done. I must admit the scale (“1 million”) was not my metric. My guiding metric was “cost per throughput”. Or roughly, how many dollars are required to do a simulation. In business, if that rate and the number of simulations are known, one can easily generate a budget request. I found this “cost per throughput” is mostly independent of the number of simulations run in parallel. In other words, “cost per throughput” was incompressible (while 1 simulation done 1000 times cost the same as 1000 simulations run in parallel, the latter took only 1/1000 of “wall time”).
Moving from in-house bare-metal clusters to cloud-based clusters is not as trivial as one would hope, particularly if “cost per throughput” is your metric. Many things on a bare-metal cluster (global storage, local storage, network, memory/cpu, cpu type) are simply present and you use them. In the cloud, they are also present, but are presented differently and there is a cost in using each one. So an optimized workflow on in-house bare-metal is almost certainly not the optimal workflow in the cloud. When Western Digital and AWS suggested we look at what scale was possible, I found the problem to be new and interesting and volunteered. WD IT also expressed an interest in making whatever workflow I came up with to be general enough to be reused for other workloads and use cases. To be honest, I thought reaching “scale” would be pretty easy, but optimizing “cost per throughput” would be a challenge and much more useful moving forward. I was correct.
It was decided that AWS Batch was the obvious choice- the write simulations are independent and the post-processing (read back and signal process) simply use these results. Job arrays would be used for the write simulation (so 1000s of simulations could be done in parallel) and the results collected by the post-process which was just another Batch job with a dependence on the first. As you may know, AWS Batch requires your task to be in a container (think Docker). It was easy to containerize the write simulation code. The only hard part is the code, as written, exploits vector computation. For CPUs, this means using AVX, AVX2 and AVX512. Availability concerns for any one instance type (at scale) was mitigated by including three executables: one for each AVX version. Then, at run time, parsing /proc/cpuinfo (or lscpu) determines which executable to launch. This made sure we were getting the most out of any CPU the simulation found itself running on. The post-processing (read back and signal processing) container was a bit more challenging since it was based on a workflow that used Octave (an open source implementation of Matlab). We could have simply pulled in an Octave from a repository but such a binary was not optimized and included many things not needed (making the size of the container quite large). Instead, I built Octave inside of a container carefully optimizing each component and including only components that were needed. This not only reduced the size of the container (good, since we pay for both storage and moving those containers to instances), but it also reduced the time for post-processing by a factor of 3 so we also win on compute cost. So, now we have two lean and computationally efficient containers to do the workflow.
Next is how to do the workflow under AWS Batch. When Batch takes a job to execute, it loads in your container and executes whatever you specify ENTRYPOINT to be in the Dockerfile. AWS shows an example of a “fetch and run”. I didn’t want to fetch the run script from S3 since at scale this could be a problem (and the associated cost for storing on S3 and transferring to the container). Instead, I baked a script into the container which simply assembled the run script on the fly. I did this by passing some environmental variables (using –container-overrides) to Batch at submission time and these variables controlled what run script was generated automatically. So far, so good. I soon found out a bit care was needed on how the simulations were run.
To reduce cost, spot instances were used. The challenge with spot instances is that they can go away with little to no warning. If you’re doing a simulation that can take an hour or so, there is a decent chance you will lose compute due to your instance vanishing. This is not new to the cloud and the usual work around is to do checkpointing of the simulation. The simulation already had checkpointing implemented so nothing was required. However, when that spot instance goes away so does its “local storage”. Clearly, the checkpoint files need to be pushed to S3 (for persistent storage) as soon as they were created. Similarly, the simulation also produce result files throughout the entire run. Fortunately, inotify (built into the Linux kernel) can tell you when a file is closed after writing for any given directory. This is perfect. At container startup, we simply construct a list of expected result and checkpoint file names (by parsing the input files) and pass that list into a spawn process that simply waits for these files to appear. This process then spawn another process that compresses (to reduce the cost of network transfer and storage) and push the files to S3. We spawn these lightweight helper processes in order not to compete for resources with the main simulation. Ah, so now we are capturing the compute as it happens so if the spot instance goes away, at retry we will simply fetch the last checkpoint and continue. Also, since the result and checkpoint files are typically not needed during the simulation, they can then be deleted from “local storage” to further reduce cost. For my particular case (small memory footprint), “local storage” can be completely eliminated since the container could create and use an in-memory file system (e.g. tmpfs) eliminating that extra cost, albeit there is some cost for transferring and storing on S3. I could find no robust cheaper way.
The next challenge appears to be specific to the cloud. Very occasionally, a container would perform slowly. Sometimes horribly slowly. By experimenting, I found by killing those containers (or the instance it was running on), Batch would retry and performance would recover. This required automation. Turns out by spawning two new processes, this was achieved. The first way was to simply track how quickly the result files appeared. If that interval was unacceptable, the process would kill the simulation and non-zero exit code would be presented to Batch flagging it to retry. The second way was to have a spawn process (bw_mem) which periodically checks the bandwidth to main memory. If it found that bandwidth was too low, again, the simulation was killed and Batch was told to retry.
The last piece was to do the actual submission of the jobs to Batch. This was more of a bookkeeping exercise (when you do tens of thousands of job submissions, you need an automatic way to keep track of what was done). Of course this job submission could be run from anywhere as long as there is a connection to AWS. I implemented it on my local laptop and amused myself submitting runs while sitting on the beach in Monterey Bay watching the sea otters play.
To truly achieve my metric (cost per throughput) some benchmarking was required. AWS provides an almost embarrassing number of instance types and sizes. By running small production runs (2000 simulations each), a large number of instance types and sizes were tested to find the optimal throughput. One surprise here was that the standard deviation of runtime was quite large (often approaching 25%). Apparently the result of not running on dedicated bare-metal. Regardless, by using the mean runtime and the historical spot instance pricing, a handful of instance types and sizes that optimized “cost per throughput” were identified. Setting up Batch’s compute environment and job queues was then easy and quickly done. Given the optimal instance type and size, we quickly ran into an internal limit of AWS Batch (5000 instances per availability zone ) which meant we were limited to 80,000 concurrent simulations (5x-10x my usual capacity and very stable). Nor did I get any panic emails from WD IT about the cost. I was pleased since this scale was sufficient. Or, if the need was there, it was easy to repeat the setup in another region or availability zone.
To get to “1 million”, AWS suggested using Univa since their scheduler had higher limits than AWS Batch. My only concern was not changing anything in the workflow for this “one-off” trial. Turns out only three trivial modifications were needed: in the submission script “aws batch submit-job …” was changed to “qsub …”, the AWS_BATCH_* environmental variables were replaced by legacy SGE_* variables in the run script and Univa grid engine required an exit code of ’99’ to retry a simulation (versus simply non-zero exit for AWS Batch). That was it! The other challenges encountered were Univa’s and you can read about them here. It should be pointed out, this Univa run did not use the “cost per throughput” metric. AWS Batch, under similar conditions, would have a theoretical limit of 460,000 [supposedly AWS Batch is now only limited by availability in a region]. By examining the instance types and sizes they used, I expect the quoted cost could be driven down significantly.
If you’re wondering if the original question was answered (ultimate AD for HAMR), I don’t know. I left Western Digital before the final big run was done. I do know the post-processing (read back and signal processing) ran into problems under Univa’s stack. Hopefully some useful information was gathered. I simply do not know. Given the required assumptions, a simple physics estimate was probably sufficient. Though, for what is the best path to the goal, the simulations should be helpful.
What I do know was that I was able to reach my metric (optimal “cost per throughput”) at a scale sufficient for HDD design and optimization. Also generated a modular workflow glue that was portable to other high throughput computing (HTC) tasks. Furthermore, it was also written so it was easy to transfer the entire workflow to Azure or Google Cloud thereby avoiding vendor lock-in. Taking a step back, I realize this write simulation (single threaded, small memory footprint and completely independent) was ideal for wide scale. However multi-threaded (or even MPI) can also be done, though I ran into latency issues on mid-scale MPI simulations.
I hope this satisfied the ‘nerd itch’ you might have had on how this “1 million core HPC cluster” was achieved. Though, in full disclosure, since the “cost per throughput” metric suggested not to turn off hyper-threading, it was “1 million vCPU HPC cluster” or “500,000 core HPC cluster”. But (as an old physics joke goes), what’s a factor of 2 between friends?
[…] on standing up a 1 million-vCPU AWS cluster won a 2019 HPCwire Editor’s Choice […]